Flow paths can be complex and follow multiple stages and whether you want to play it safe or simply do not have all the needed data, testing in production might not be the most appropriate solution.
For those cases, the dry run allows you to safely observe a transaction through your path based on variables you manually defined.
To perform a dry run, you will need to supply data for at least one of the triggers.
Depending on the trigger nodes used in your flow, one or more buttons will be available to select from.
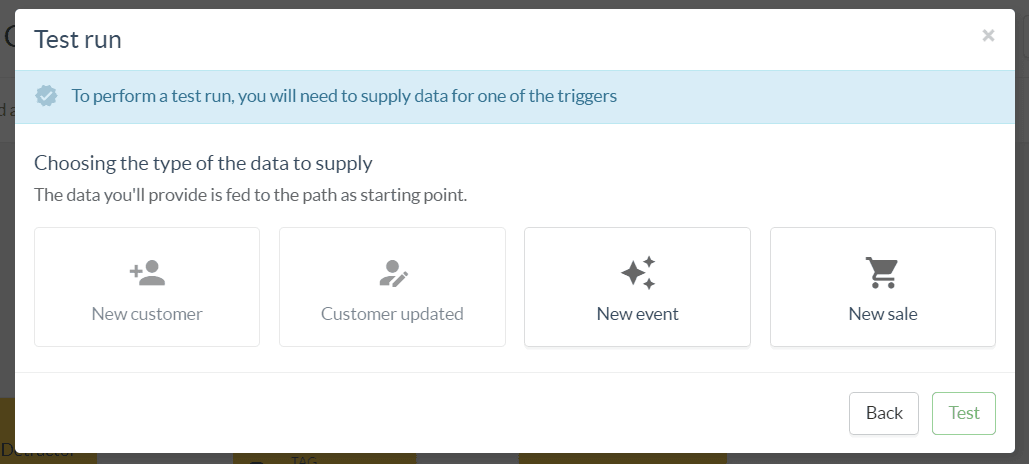
Once you have selected the trigger, you will need to provide the data for the required fields, and any other fields you need to match your trigger filter.
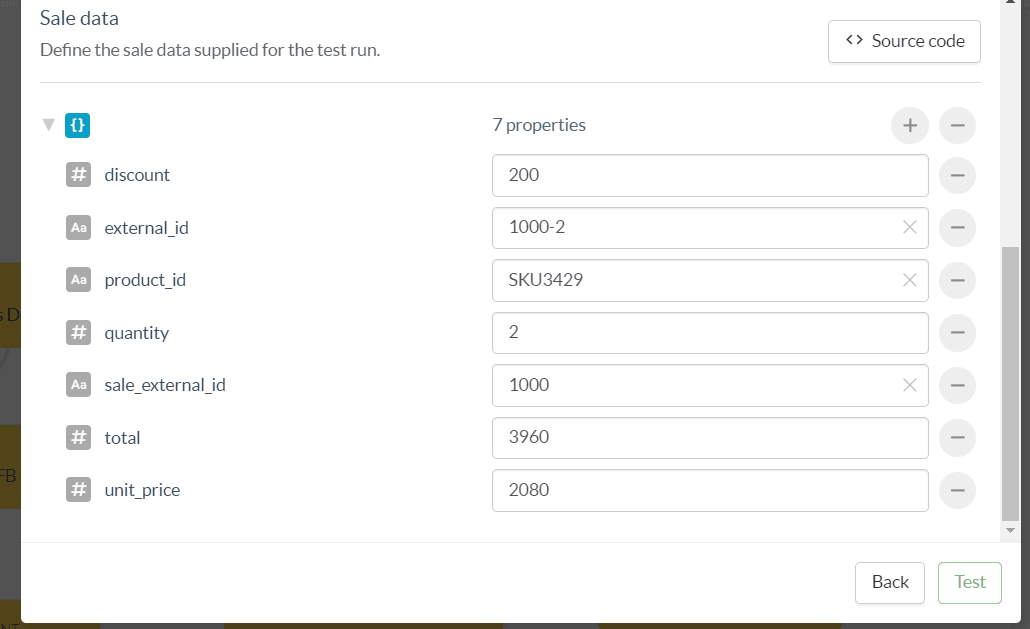
In the example of an Sale based trigger, the required fields will be needed for two data types: The Customer who received the event, and the Sale’s own data.
Mandatory fields are Customer ID, Sales date and Sales external ID. The date will be filled automatically with the current date and time.
By default, the dry run interface offers a field + value text boxes format, but you can toggle a source code view if pasting a snippet of json is more convenient.
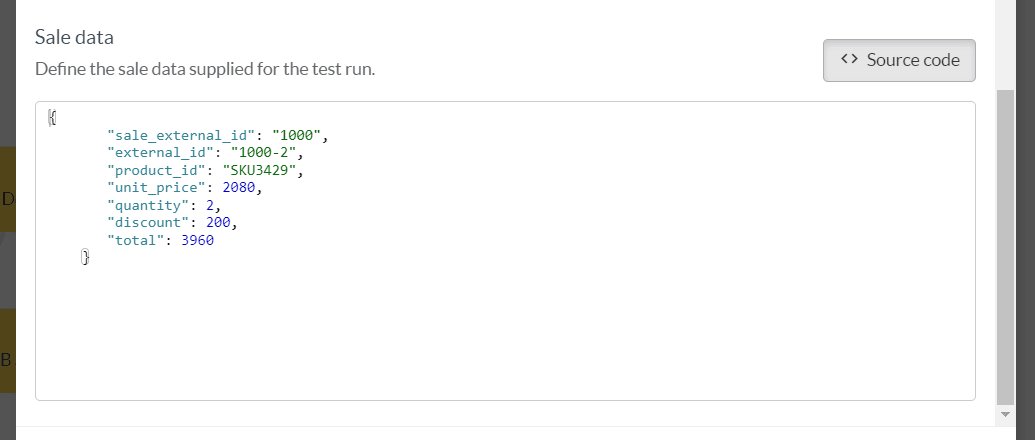
Once the required fields are properly filled, you can enrich the data by adding any extra properties needed to match the trigger filter, or reflect real life variables the Flow will need to deal with.
To add a new property, click the + button and type in the field key. Please note that the key syntax must match the existing field. In case of doubt, please refer to the data schema page where you can toggle the default fields to see the complete list of fields labels per data type.
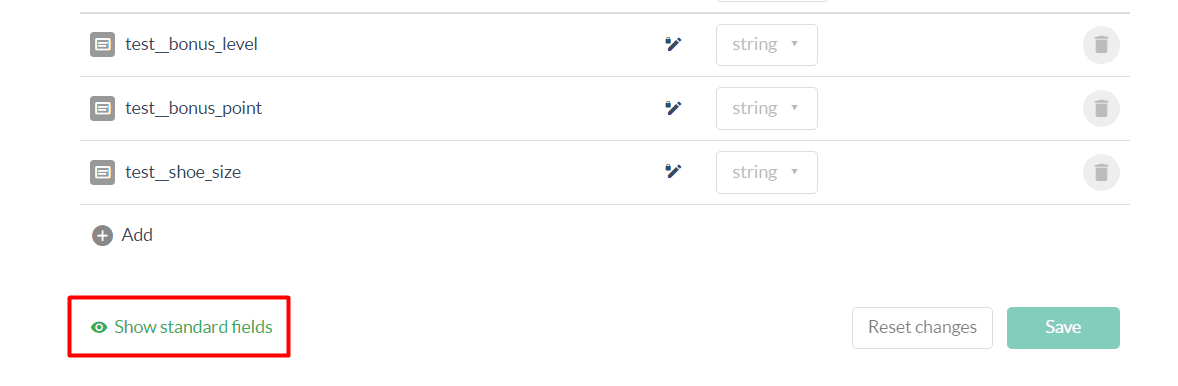
For triggers referring to products within a Sale, in an Event or similar data, you will need to reproduce that structure in the dry run’s test data.
The example below shows a Sale trigger where only the brand “Nike” will match the filter. We need to reproduce the structure for sales.products.brands=Nike
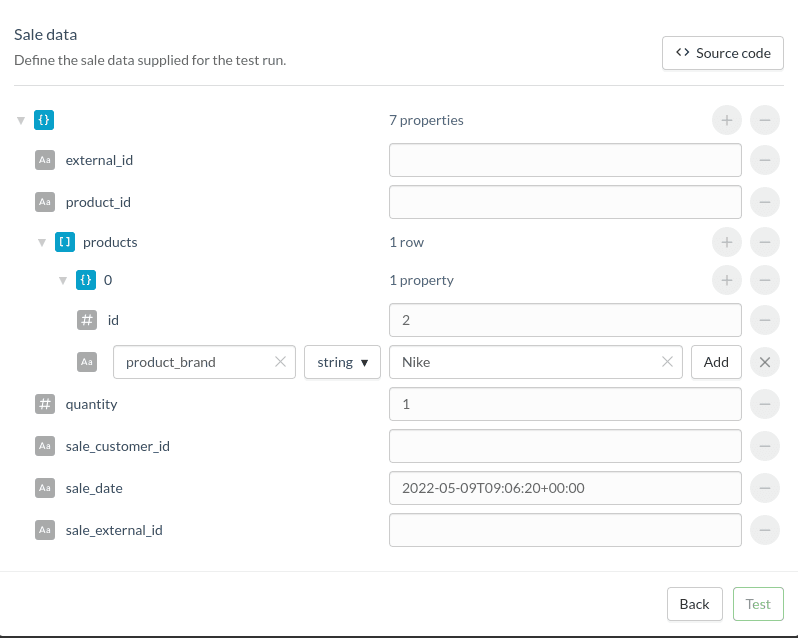
Our best practice recommendations is to include all the variables used in filtering in the data used in the dry run. This way the dry run will go through as intended and not leave you stuck on the first step "Did not match the filter criteria".
Once the data is configured, just hit the Test button and the dry run will proceed and render the steps involved in the path with simulated timestamps for the eventual delay nodes used.
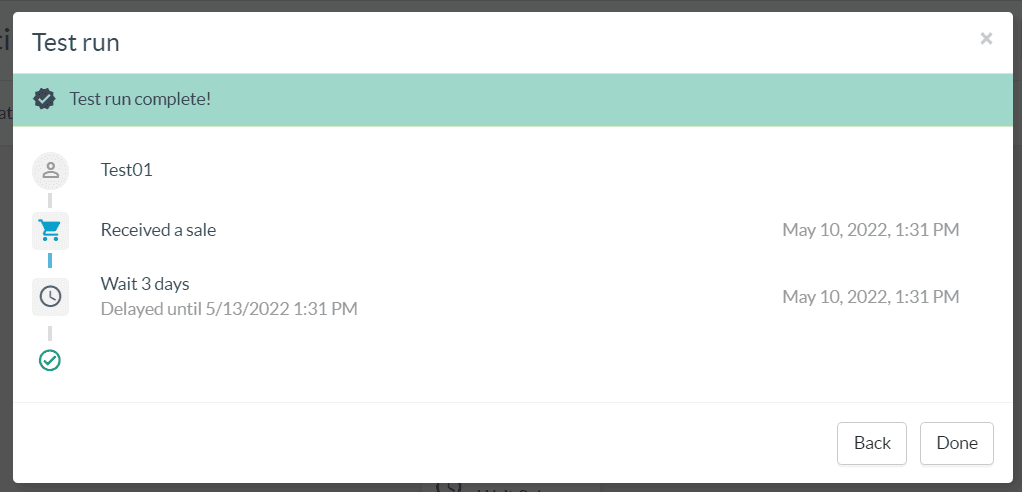
As with all testing features, please note that the dry run is only available after you have saved your draft at least once.